Parsing HTML Tables from Incoming Email via Power Automate
Alternatively, how to extract 93 rows of data from 48,000 lines of HTML


Initial Disclosure
This is not a perfect pattern! What I outline here is not enterprise-grade by any means. The whole thing would fall on its face, if scaled. 😀
I approached this problem (and corresponding solution) as a low-risk, thought exercise.
The Problem
A few weeks ago, one of our data engineers approached me with an issue: a vendor that handles a bit of customer outreach for the company will only return results to us in an HTML table, emailed weekly. There's no API to hit, no CSV we can grab. Nothing!
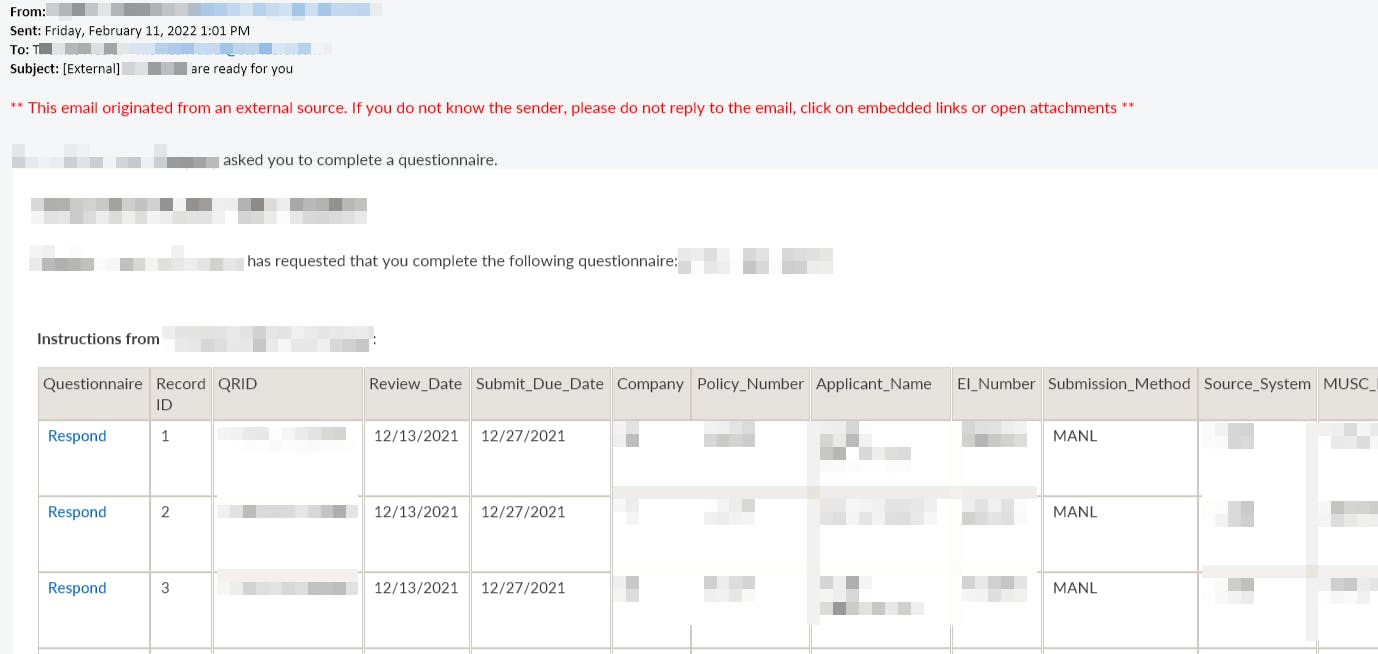
How do we get that tabular information into a database so we can report on it?
Thinking Through It
Sending HTML tables via email is a decent way to enable folks to quickly view data, but it's a terrible way to share data. There's no direct path to ingest it, and all of the information is wrapped in heavy layers of HTML - both the table structure itself and the surrounding message body.
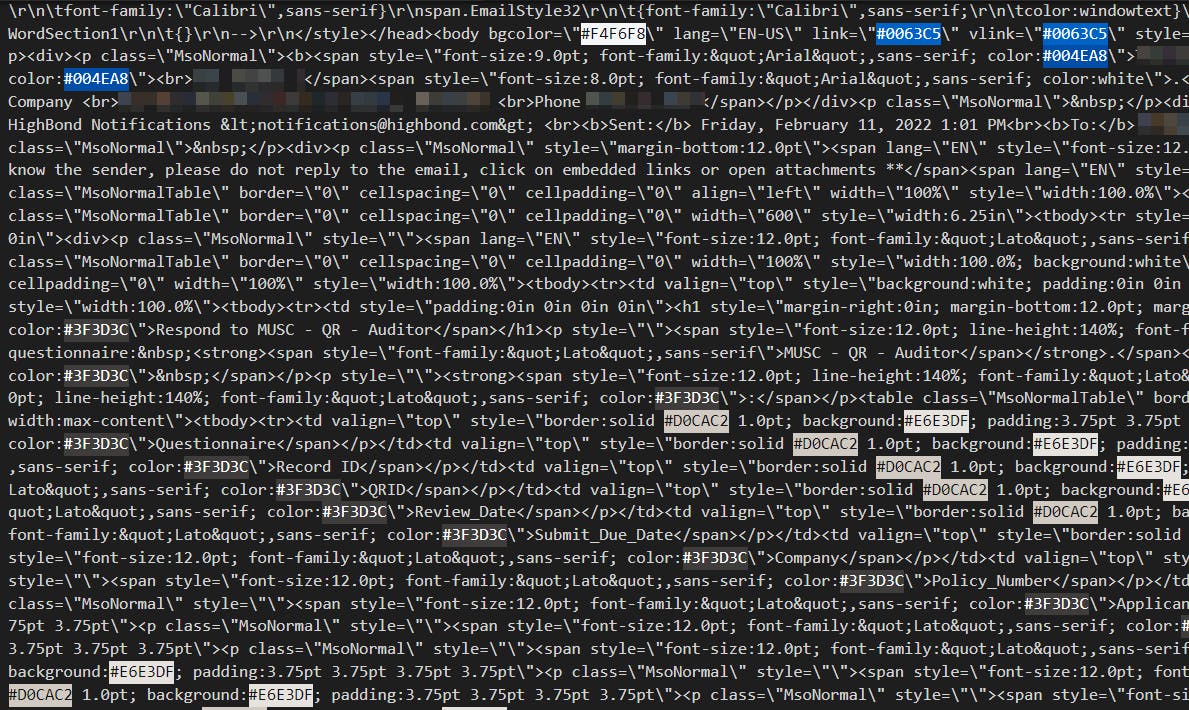
What makes this tricky is that every scenario is unique. Your "how do I get tabular data out of an email body" problem is almost certainly different from this one. Table structures vary, different systems generate message bodies in different ways, some inject a ton of HTML "junk" and some don't.
Our table contained 93 rows of data - not very much. Those 93 rows of data, however, were wrapped inside 47 nested tables comprising 48,000 lines of HTML ... yikes!
Solutioning with Power Automate
While there's no one-size-fits-all approach to solving this, there are some proven methods we can employ!
1) I started by bringing the email message body into a htmlConversion action:
☝ Don't be fooled by Automate's award-winning UI... there's a value in there!
2) The original HTML goes in, and something resembling plaintext comes out after the HTML structure and syntax gets stripped out:
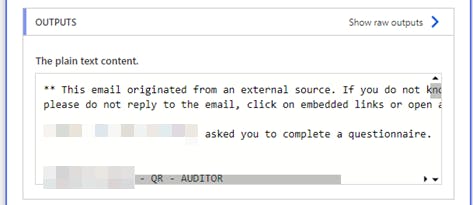
3) I used a "landmark" method next, finding a reliable chunk of text, in a fixed position near the start and end of the table. Using a subString expression with two Compose actions allowed me to isolate the table:
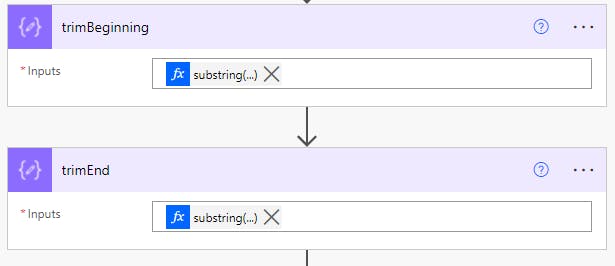
substring(
body('htmlConversion'),
add(
indexOf(
body('htmlConversion'),
'Reviewer_Job_Title'
),
20)
)
The second substring expression is quite similar. You find your landmark, then walk n number of characters forward or backward from there.
4) I borrowed this next method after some web searching yield a great article on the subject.
Now that we have the table values isolated in plaintext, we can split them into an array.

The expression inside is a bit tricky. Let's walk through it, starting from the inside out:
split(
trim(
replace(
uriComponent(
outputs('trimEnd')
),
'%0A',
'~~'
)
),
'~~')
- Take the trimmed plaintext...
- Encode it
- Replace the linebreaks with an arbitrary string ("~~")
- Split the entire thing into an array, using the arbitrary string
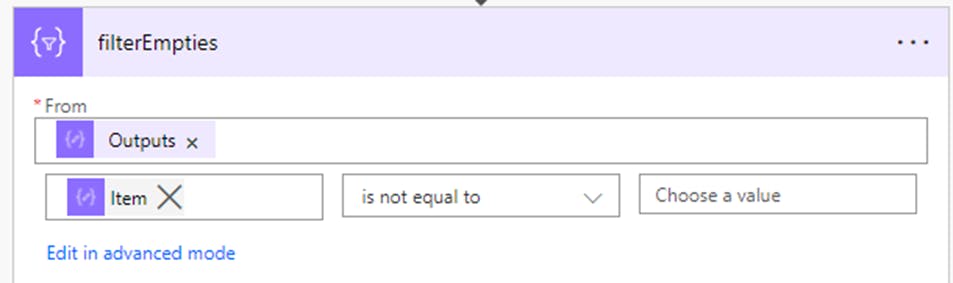
5) We're almost there! The next step is to dump any empty nodes from the array, like this:
6) After that, we're pretty much home free. We can iterate over the array, and record the data wherever we like (SQL, SharePoint, etc.). I used SharePoint in this example.
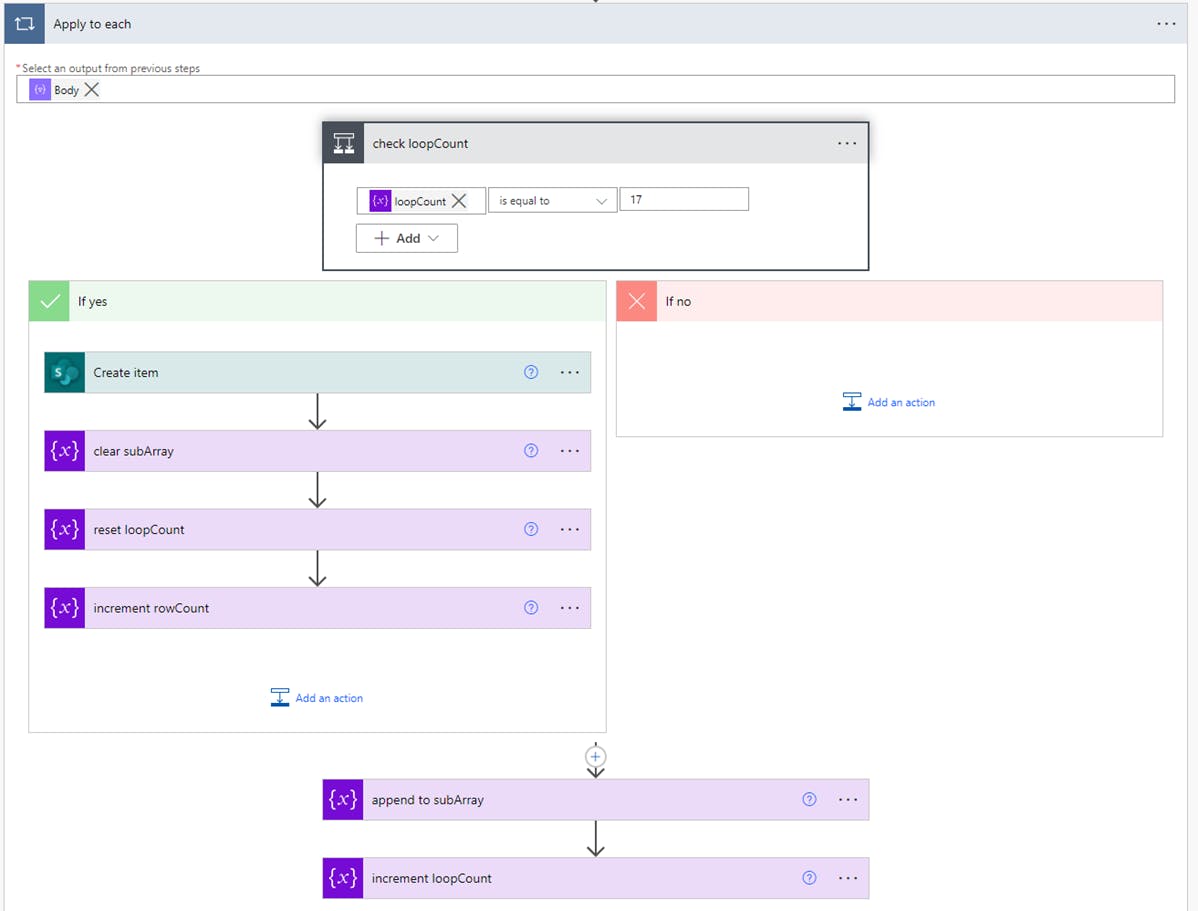
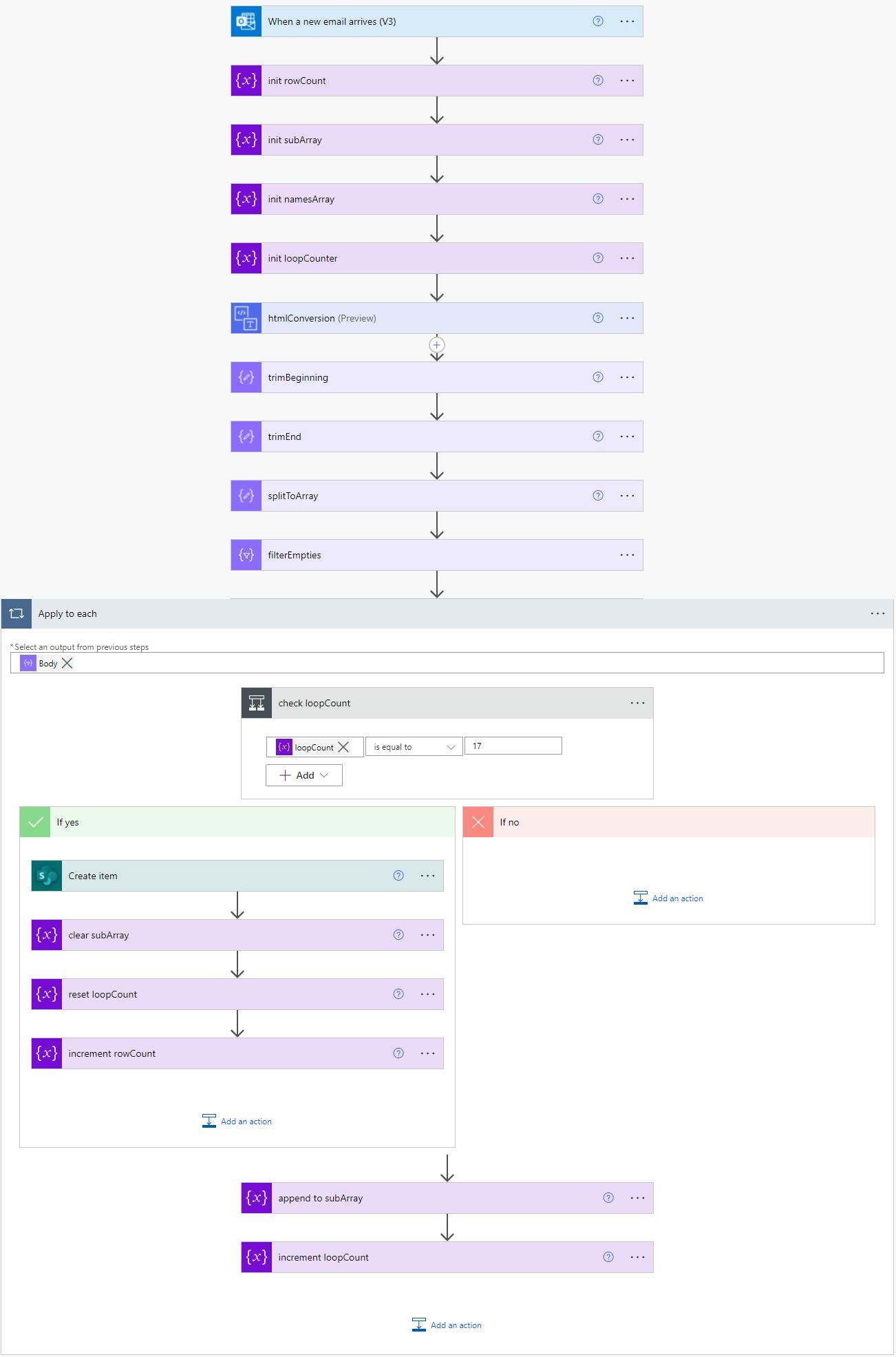
The method I employed is a bit flaky - but it works. Since I knew the table had 17 columns, I looped through the primary array until I had a complete row, creating a temporary array in the process. Once my counter hit 17, I cleared the temporary array and reset the sub counter. Rinse, repeat, until the whole thing is processed.
You will want to unencode the values, as you create your temporary array:
uriComponentToString(items('Apply_to_each'))
What Are the Weak Points? How Could We Improve This Method?
Creating an object for each row, instead of manually mapping array position. Would be more elegant, but not really needed in this case.
Relying on “landmarks” in the HTML is really flaky. If the vendor changes anything in their email format, even something trivial like their logo, this solution may stop working.
Looping a fixed number of times only works if table columns are consistent
The flow runs very slow due to serial concurrency. About 12 minutes to process 93 rows of data. Solution not scalable.
Final Flow