


Handling Paginated Results from Microsoft Graph with Azure Data Factory
Paginating through Graph API results using @odata.nextlink in ADF copy activities


This topic is covered in a handful of blog posts, forum topics, etc. but none of the information I found recently got me 100% of the way there. That can happen with methods involving two evolving services - Azure Data Factory and Microsoft Graph - information becomes out of date.
Here's what worked for me in early 2023!
Prerequisites
Even though some of these are detailed topics, I am going to gloss over them since they are covered in-depth elsewhere on the web:
Register an Azure App for use as a service principal (later) with your data factory
Grant the application appropriate roles for your intended use of Graph
Store the client secret value for the app in Azure Key Vault
Enable managed identities for your data factory
Give the managed identity for your data factory the appropriate role on the Key Vault (to retrieve stored client secret)
Configure a data sink to store the Graph results, and ensure the data factory has permission to write there
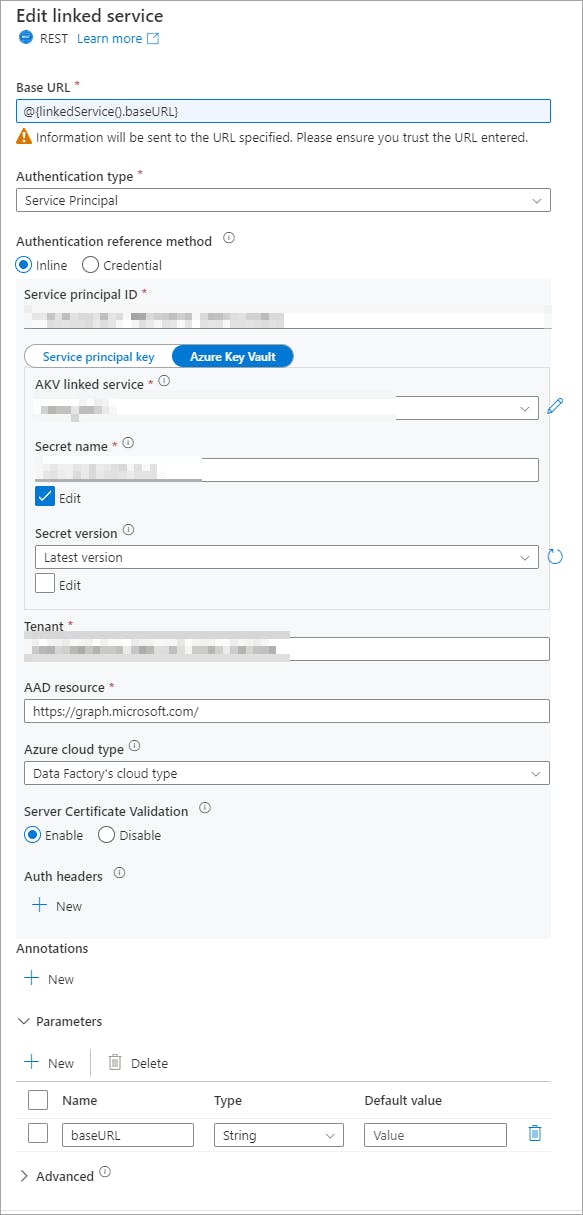
Create a new Linked Service within ADF (type: REST)
Set the Authentication type as Service Principal
Use the Azure Key Vault method to retrieve the client secret from AKV
Parameterize the Base URL value
This will get you something like this:
Dataset, Pipeline and Activity Setup
Create a new Dataset using the new Linked Service you created (above steps)
You can parameterize the baseURL value if you'd like to use one Dataset for multiple Graph queries.
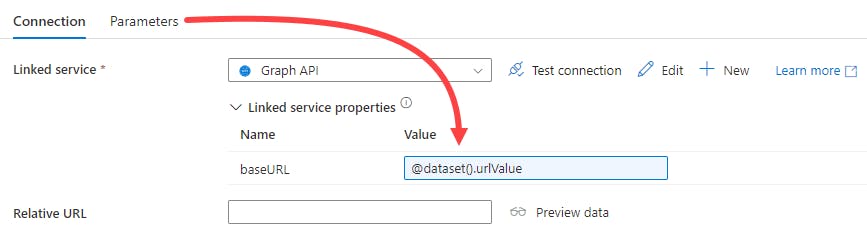
Otherwise, provide a fixed Graph API endpoint value within the Dataset, like:
https://graph.microsoft.com/v1.0/users?$select=id,accountEnabled,createdDateTime,department,displayName,employeeId,employeeType,jobTitle,mail,userPrincipalName,userType,manager,employeeHireDate&$expand=manager($select=id)
Create a new Pipeline and add a Copy Data activity
Configure the Copy Data activity to use the Dataset you created
Delete the automatically-supplied Pagination criteria (RFC5988)
Add a new Pagination Rule, like this:

Your source definition within the Copy activity should look something like this:
"source": {
"type": "RestSource",
"httpRequestTimeout": "00:01:40",
"requestInterval": "00.00:00:00.010",
"requestMethod": "GET",
"paginationRules": {
"AbsoluteUrl": "$['@odata.nextLink']"
}
}
Now, when your Copy Data activity executes, it will keep fetching results from Graph until the @odata.nextlink is no longer present in the result body, at which point it will start the sink activity.
Note: this is my first time using the new Neptune editor on Hashnode ... forgive any oddities with the numbered list formatting... I am in a bit of a hurry and will try to fix the markdown later